L’IA dans la sphère travail (1)
1.L’IA et les algorithmes dans la sphère travail, de quoi parle-t-on ?
Cet article est le premier d’un feuilleton sur les algorithmes et l’intelligence artificielle dans la sphère travail. Aujourd’hui, nous nous intéressons aux concepts de bases des algorithmes et de l’intelligence artificielle.
" La donnée et l’intelligence artificielle (IA) sont amenées à prendre de plus en plus de place dans la transformation du monde du travail. "
Elisabeth Borne, ministre du Travail, de l’Emploi et de l’Insertion, dans la feuille de route du ministère sur les données, les codes sources et les algorithmes (septembre 2021).
“Algorithmes”, “intelligence artificielle” : on entend de plus en plus parler de ces concepts dans le secteur public et notamment dans la sphère travail. Que signifient-ils vraiment ? Quelles opportunités offrent-ils ? Quels enjeux soulèvent-ils ? Depuis quand sont-ils présents dans l’administration ? Dans le premier article de notre feuilleton, nous vous donnons quelques éléments de définition et de contexte.
Qu’est-ce qu’un algorithme ?
Plusieurs définitions existent pour expliquer le concept d’« algorithme » (voir par exemple celle de la CNIL). Très simplement, un algorithme est une suite d’étapes qui permet d’arriver à un résultat… comme une recette de cuisine.
Commençons par rassembler nos ingrédients. Dans le monde du numérique, il s’agit de « données », c’est-à-dire des éléments tels que des chiffres, du texte, des images, etc.. Mixons le tout numériquement en suivant la recette (la suite d’étapes). Nous obtenons ainsi notre plat : le résultat. Beaucoup de choses peuvent ainsi être considérées comme des algorithmes.
Le guide en ligne d’Etalab sur le sujet donne des exemples d’usages d’algorithmes.
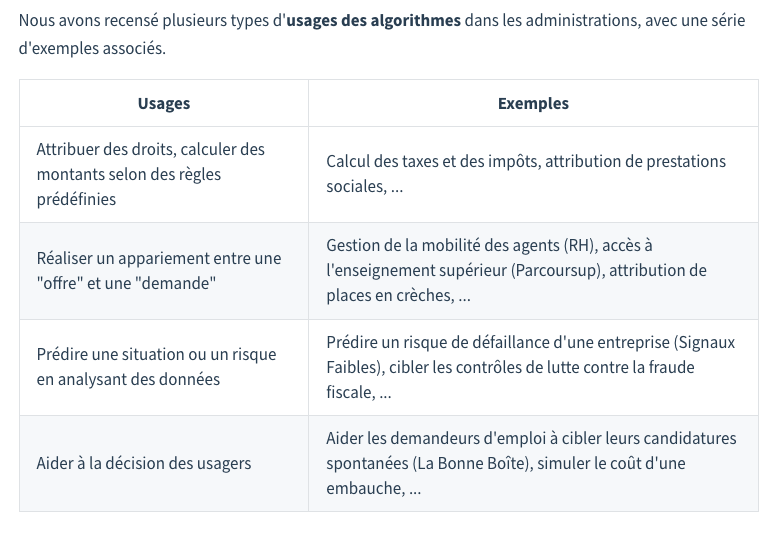 Capture d'écran du guide en ligne d'ETALAB
Capture d'écran du guide en ligne d'ETALAB
Les algorithmes, des outils présents depuis plus de cinquante ans dans l’administration
Comme le rappelle Etalab (le département de la direction interministérielle du numérique en charge de la politique des données de l’État) dans un webinaire sur la transparence des algorithmes publics, l’administration française a recours à des algorithmes depuis plusieurs décennies. L’automatisation du calcul des impôts remonte aux années 1950-1960.
Si les algorithmes sont présents dans la sphère publique depuis longtemps, le sujet est remis sur le devant de la scène par l’arrivée de nouvelles techniques algorithmiques : aux algorithmes “classiques”, aussi appelés “systèmes de règles”, s’ajoutent les techniques algorithmiques d’”intelligence artificielle”, telles que l’apprentissage automatique (machine learning) et l’apprentissage profond (deep learning).
Systèmes de règles, machine learning, deep learning : les différents types d’algorithmes
Les systèmes de règles
Les algorithmes utilisés historiquement dans l’administration (comme celui du calcul des impôts ou des allocations) sont ceux qui appliquent des règles établies par les humains qui sont ensuite transcrites en langage informatique. On les appelle des “systèmes de règles”.
Dans l’administration, il s’agit notamment de règles présentes dans les textes législatifs et réglementaires. Par exemple, les règles de calcul des impôts sont fixées chaque année par le Parlement.
L’épisode 2 de ce feuilleton détaillera un exemple de système de règles dans la sphère travail : le calcul de l’aide au retour à l’emploi.
- Il existe ensuite des algorithmes qui, dans le langage commun, se distinguent des systèmes de règles : les algorithmes d’intelligence artificielle.
Les algorithmes d’intelligence artificielle
Tout comme le terme “algorithmes”, celui d’“intelligence artificielle” est plus ancien qu’on ne le croit : sa première utilisation date de 1956 (voir le rapport “Donner un sens à l’intelligence artificielle” de la mission Villani, mars 2018). Il englobe toutes sortes de techniques mathématiques qui servent à reproduire la manière dont les humains raisonnent. En théorie, donc, il recouvre aussi les systèmes de règles dont nous parlons plus haut.
Cependant, il est maintenant employé de manière courante pour parler d’algorithmes spécifiques : ceux qui reposent sur l’apprentissage automatique (machine learning en anglais). En réalité, l’apprentissage automatique est un sous-ensemble de l’intelligence artificielle, mais les deux termes sont souvent confondus dans le débat public.
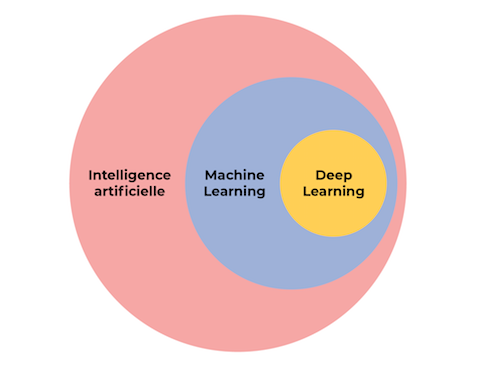
Diagramme issu du cours “Open AI” de Benjamin Ejzenberg et Anna Choury, disponible sur le site OpenClassrooms.fr, licence CC BY-SA 4.0.
L’apprentissage automatique (machine learning)
Contrairement aux systèmes de règles, les algorithmes d’apprentissage automatique ne sont pas programmés pour effectuer une tâche en suivant des étapes prédéfinies par des humains, mais pour définir eux-mêmes les étapes nécessaires pour effectuer cette tâche, à partir de données qui leurs sont fournies.
L’apprentissage (ou entraînement) est ce qui va permettre de construire l’algorithme. Les data scientists donnent à l’algorithme beaucoup de données à analyser, et l’algorithme utilise ces données à l’aide de méthodes statistiques et de sciences des données pour apprendre et déduire les règles lui-même.
- Ce sont les techniques de machine learning qui vont permettre de faire des prédictions (usage n°3 dans le tableau d’Etalab). Dans la sphère travail, on trouve par exemple l’outil “La Bonne Boîte”, qui permet d’identifier les entreprises susceptibles d’embaucher dans les 6 prochains mois. Le fonctionnement de cet outil sera détaillé dans un prochain article.
Cette méthode, qui a désormais une dizaine d’années, a été rendue possible par l’augmentation des données disponibles et de la puissance de calcul des ordinateurs. Son efficacité repose en grande partie (mais pas uniquement) sur la quantité et la qualité des données fournies “en entrée”.
Deep learning
On entend également souvent parler de deep learning (apprentissage profond) : c’est une sous-catégorie du machine learning et l’une des méthodes d’intelligence artificielle les plus avancées techniquement. L’architecture des techniques d’apprentissage profond est inspirée du cerveau humain.
Ces techniques permettent d’analyser les données “non-structurées” (tout ce qui n’est pas des données chiffrées, comme les images, les textes, les sons, etc.) de manière plus efficace que les techniques de machine learning traditionnelles. C’est grâce à ces techniques que le traitement du langage a pu énormément progresser ces dernières années : les traducteurs automatiques sont maintenant bien plus performants qu’il y a une décennie.
En revanche, pour obtenir de bons résultats, le deep learning a besoin d’encore plus de données que le machine learning, ce qui pose des difficultés car il est rare de trouver des gros jeux de données d’une bonne qualité.
Dans la suite de ce feuilleton, nous observerons des cas concrets d’utilisation de chaque type d’algorithme dans la sphère travail
Vous menez un projet algorithmique ou d’IA dans la sphère travail ? Vous cherchez des ressources pour en commencer un ? N’hésitez pas à nous le faire savoir !
En savoir plus…
- Rapport de la CNIL : "Comment permettre à l'Homme de garder la main ? Les enjeux éthiques des algorithmes et de l'intelligence artificielle", décembre 2017
- Rapport de la mission parlementaire menée par le député Cédric Villani : Donner un sens à l’intelligence artificielle : pour une stratégie nationale et européenne, mars 2018
- Le site de la stratégie nationale pour l’intelligence artificielle
- La feuille de route ministérielle 2021-2023 des données, des algorithmes et des codes sources du ministère du Travail, de l’Emploi et de l’Insertion, septembre 2021.
- Découvrez Publicodes, un langage pour construire des simulateurs et des outils de calcul à partir de textes légaux.
- Le cours en ligne gratuit “Open IA”, pour s’initier aux notions de l’intelligence artificielle.
- Les ressources d’Etalab (guide et webinaires) sur la mise en œuvre des obligations de transparence et de redevabilité relatives aux algorithmes publics.